A few weeks back I built a loan-approval workflow as part of a larger banking platform POC to test agentic capabilities. The loan workflow uses three agents, a human approver, and a conversational assistant for customers. For now we'll focus on explainability, the system's ability to always tell you why it decided what it decided. It might sound academic, but if you've ever written an if/else and logged it to a table, you already know how to build it.
Let me walk you through what actually happens when someone applies for a loan, because the whole thing is less mysterious than the word makes it sound.
A customer applies, and the agents go to work
Jeremy D asks for $15,000 over 36 months. The customer fills in a form and hits submit — that's the whole customer experience at this stage.
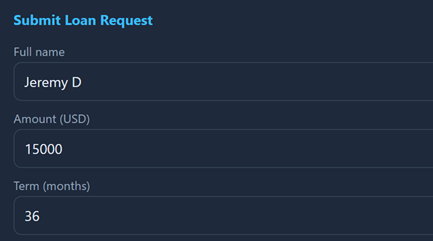
Under the hood, a chain of agents wakes up. The loan-api creates the record. A credit-agent pulls a credit profile. An approval-agent runs the risk assessment. That last step is where explainability lives, and here's the important bit: the agent doesn't just spit out a number. It produces a scorecard.
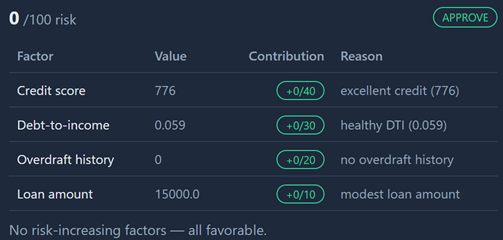
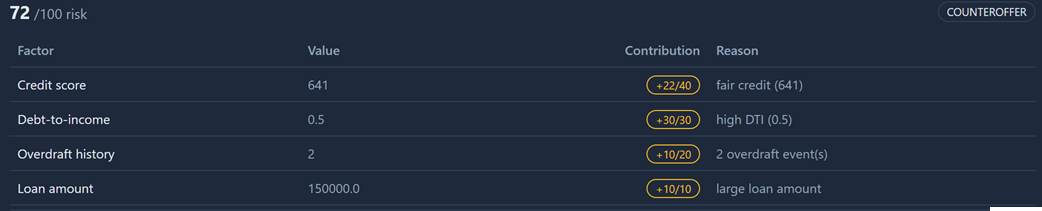
Jeremy comes back as 0/100 risk — every factor favorable, recommendation to approve. But the score is the boring part. Next to it is a breakdown: each factor has a value, a contribution, and a plain-English reason. It gets more interesting when the applicant isn't squeaky clean. Corbin Dallas wants $150,000 over 90 months and lands at 72/100, decline:

Credit score 641 contributed +22 of a possible 40 points ("fair credit"), debt-to-income of 0.5 maxed out at +30/30 ("high DTI"), two overdrafts added +10. Ruby Rhod's modest $5,000 request sits in between at 25/100 — approve, but with an elevated-DTI flag.
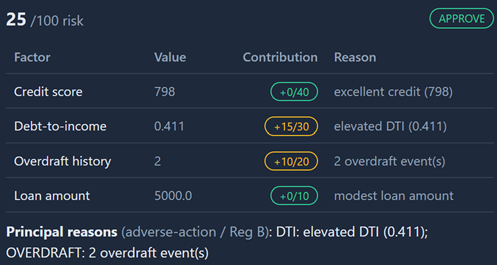
That breakdown is explainability, and notice what it actually is — a weighted sum with reason strings attached. You don't need a PhD or a SHAP library to produce it. You decide which factors matter, assign weights, and write the sentence that goes with each one. The model can do the scoring; the explanation is something you design.
The human decides — and the system remembers who
Now it goes to the loan officer's review queue. Every request shows its risk badge, a status of pending approval, and a row of buttons: Approve, Reject, Modify, Counter, Why, Audit.
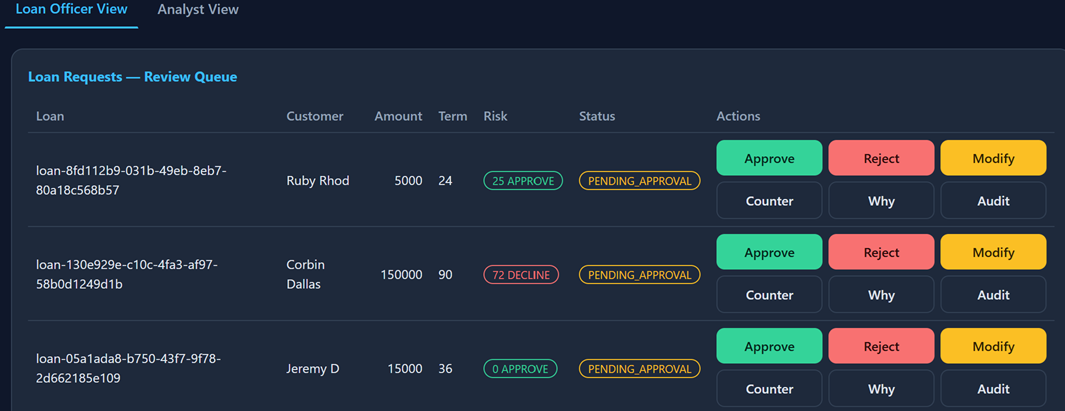
This is the human-in-the-loop, and it matters that the agent recommended but did not decide. For Corbin's risky $150k, the officer doesn't just reject — they hit Counter, reshaping the terms to bring the risk down, then approve.
The agent built the case; the human made the call. And every move lands in an append-only audit trail.

loan-api creates the loan, credit-agent writes the profile, approval-agent logs the risk assessment — then jeremy@datadinosaur.com (a verified identity, not a dropdown selection) logs a counteroffer, then an approval. You can read the entire life of a decision top to bottom: which agent did what, which human overrode what, and when, down to the microsecond.
If you're in banking, this is where explainability stops being nice-to-have. A declined applicant is legally entitled to know why — that's the adverse-action notice under Regulation B. Notice the scorecard literally labels Corbin's drivers as "Principal reasons (adverse-action / Reg B)." Model risk governance (SR 11-7) wants the same thing from the other direction: show your work. The audit trail and the reason codes aren't features I bolted on for fun, they're the artifacts a regulator and a CIO both ask for first.
The explanation follows the customer home
The last two steps close the loop. An analyst opens the conversational assistant and asks about Corbin's loan; the answer is grounded in the actual data products, and it even flags that the human override differed from the system recommendation.
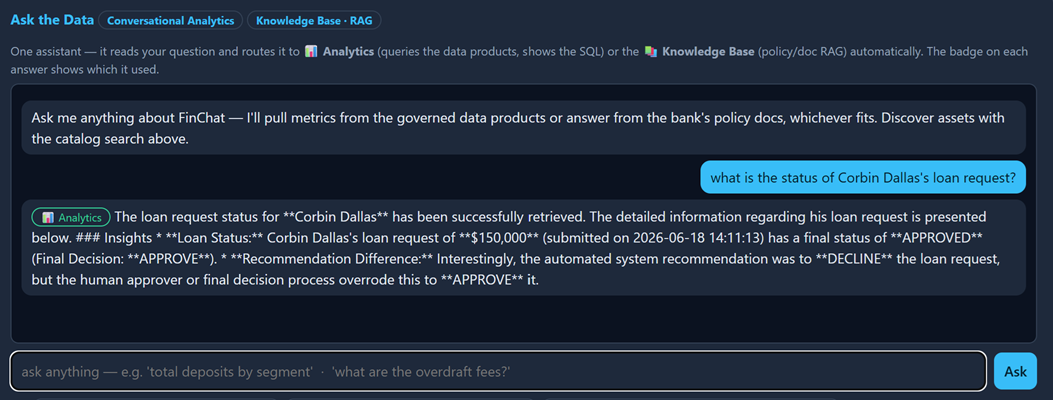
Then the customer asks "what's the status of my loan?" and gets a grounded reply: approved, original recommendation was to decline because of fair credit, high DTI, and two overdrafts, final decision made by a named approver.
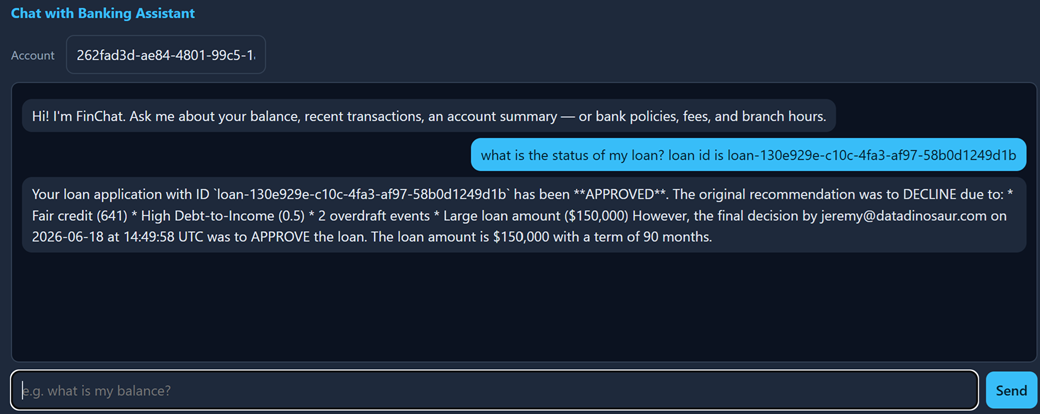
No hallucination — the same explanation that started in the agent flows all the way to the person it's about.
Why this matters
Explainability is just the discipline of always being able to answer "why did the system decide this?" in terms a human can understand and act on. You build it with things you already use: weighted scores, templated reasons, an append-only log, verified identity, and grounded retrieval so the AI explains with real data instead of inventing a story.
The teams that win with AI over the next few years won't be the ones with the cleverest models. They'll be the ones who can explain a decision to a regulator, a customer, and a skeptical executive — using the same trail. If you can't say why, you don't have a system you can put in production. You have a demo.
0 Comments
Leave a Comment